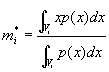Заборовский В.С., Рязанов М.Г.
Управление в компьютерных сетях: концепция сетевых процессоров *
.Введение.
Развитие компьютерных систем открывает новые перспективы для создания систем управления техническими объектами и комплексами. Применение сетевых технологий в системах управления позволяет не только повысить производительность и обеспечить более рациональное использование ресурсов вычислительных устройств, но и создать системы управления нового класса [1].
Современная компьютерная инфраструктура чаще всего ассоциируется с Интернет или корпоративными Интранет сетями. Сегодня сеть Интернет представляет собой огромный и в значительной мере случайно организованный конгломерат информационных ресурсов, обладающий качествами подлинно интеллектуальной среды, и создает предпосылки для появления совершенно новых технологий обработки и представления информации. Наряду с аппаратными компонентами протоколы межсетевого взаимодействия и программные приложения составляют основу этих технологий. При их создании широко используется новый подход к управлению информационными ресурсами на основе специальных программных модулей, получивших название интеллектуальных агентов. Каждый такой агент обеспечивает управление доступными для него информационными ресурсами, используя для этого набор собственных целевых условий и внешних задающих воздействий. С технической точки зрения агент может представлять собой перемещаемый по сети фрагмент исполняемого программного кода, для взаимодействия с которым используются стандартные сетевые интерфейсы.
Таким образом, в процессы управления добавляется новая возможность воздействия на состояние объекта управления путем передачи не только самого управляющего воздействия, но и воздействия на программные компоненты (агенты), которые реализуют алгоритм управления. Компоненты могут быть стационарными или мобильными. В первом случае каждый системный ресурс (пропускная способность каналов, загрузка процессора, используемая память и т.д.) имеет своего стационарного интеллектуального агента, который функционирует как менеджер этого ресурса в процессе обработки запроса на его использование. Во втором случае мобильные интеллектуальные агенты становятся средством реализации новой универсальной технологии создания различных распределенных сетевых приложений. Они получают оперативные данные о состоянии объекта уже непосредственно в той точке сети, где необходимо реализовать требуемое управляющее воздействие. При этом в самом алгоритме функционирования агента могут учитываться координирующие воздействия от других компонент или команды оператора. В результате управление носит иерархический характер, при котором на нижнем уровне реализуются алгоритмы управления с местной обратной связью и малыми задержками, а на верхнем ¾ глобальная оптимизация и координация управляющих воздействий. Для практического использования этой технологии требуется, чтобы для организации обратных связей применялись стандартные сетевые интерфейсы, а оптимизация осуществлялась на базе математической модели процессов управления.
Для реализации описанного подхода интеллектуальные агенты должны взаимодействовать как друг с другом, так и с пользователем информационных ресурсов. С точки зрения пользователя агенты суть программные модули, обладающие способностями к оперативному анализу данных, к адаптации к изменяющимся условиям и к активному обмену информацией с другими программными агентами для достижения цели сформулированного им запроса. При этом суть запроса может относиться как к получению доступа к определенным данным, так и к резервированию части доступных сетевых ресурсов с целью обеспечения заданного качества информационного сервиса.
Переход от прямого манипулирования стандартными опциями программного обеспечения, когда человек инициирует все процедуры взаимодействия, к непрямому управлению в форме задания целей управления и передачи функций их достижения интеллектуальным агентам представляется весьма привлекательным с практической точки зрения. Этот подход позволяет создать локальный цифровой alter-agos, который в отдельных областях деятельности человека может представлять его интересы в соответствии с делегированными ему функциями, т. е. фактически стать proxy-agos [2].
Агентный подход имеет более естественную и простую модель распределенного асинхронного взаимодействия, чем традиционные средства, например процедуры RPC. Это важно и для автоматизации задач сетевой конфигурации, контекстного поиска или управления динамическими выделенными ресурсами. В таких задачах агенты играют также роль менеджеров межсетевых процессов взаимодействия. При этом возможность перемещения мобильных агентов, а следовательно, и локализация алгоритмов в точках, где обеспечивается наиболее эффективный доступ к оперативным данным, позволяют уменьшить задержки при передаче данных через сеть, а также расширить возможности защиты данных от несанкционированного использования.
Сам антропоморфный термин "агент" предполагает реализацию тех или иных интеллектуальных функций и требует использования специальных инструментальных средств и алгоритмов адаптации. В этих условиях агент должен:
Спецификация плана может быть задана с помощью лингвистических аргументов/параметров, либо как набор целей, сформированных в виде продукционных правил. Поэтому сам механизм планирования может также носить иерархический характер, что позволяет разделить процедуру планирования на мета- и базовый уровни.
На мета-уровне используется объектно-интерактивный протокол взаимодействия, обеспечивающий ассоциативный доступ к ресурсам путем разбора параметров входных запросов. На оперативном уровне используется объектно-процедурный протокол и формируется последовательность процедур, обеспечивающих непосредственное взаимодействие с управляемыми ресурсами или приложениями. Информационные связи между различными компонентами таких приложений показаны на рис.1.
|
Агенты |
||
|
Протоколы и языки взаимодействия |
||
|
Tcl |
Java |
Sheme |
|
Сервер приложений |
||
|
Транспортный механизм |
||
Рис. 1. Модель взаимодействия агент-сеть
Нижний уровень этой модели является интерфейсом к используемому сетевому транспортному механизму передачи данных. Следующий уровень реализует сервер, запускаемый на каждой машине, участвующей в межсетевых процессах взаимодействия. Это взаимодействие реализуется с помощью механизмов передачи сообщений и потоков данных с их аутентификацией. Третий уровень содержит среду выполнения, поддерживающую различные языки взаимодействия агентов. Последний уровень содержит виртуальный образ самого агента, составленный с помощью алгоритмов его функционирования. Сами алгоритмы реализуются с помощью интерпретации входных данных, протоколов взаимодействия и ресурсов, доступных серверу.
В случае использования описанной технологии архитектура всей системы, реализующей агентный подход, имеет вид, показанный на рис 2.
Рис. 2. Архитектура взаимодействия в агентно ориентированной сети
В отличии от традиционной архитектуры сети, например Интернет, в которой существует четкая регламентация правил взаимодействия между уровнями, в новой архитектуре обратная связь формируется в процессе взаимодействия агентов.
Заметим, что развитие
WWW, как глобальной информационной субсети на базе Интернет, породило два новых класса задач сетевого управления.Первые задачи связаны с автоматизацией функций анализа данных и обработки контекстных запросов в
WEB пространстве. К этому классу относятся задачи сканирования по ключевым словам, формирования виртуальных корпоративных хранилищ данных, обработки защищенных транзакций.Второй тип задач относится к созданию универсального интерфейса для удаленного сетевого взаимодействия с техническими устройствами с целью передачи и/или получения от них данных и их последующей обработки. В свою очередь эти задачи можно разделить на задачи реального времени, изохронные и мультимедийные приложения.
Важным направлением применения описанной расширенной трактовки понятия "информационные ресурсы" является управление сложными динамическими объектами. При этом могут применяться алгоритмы, использующие в цепи обратной связи информацию о состоянии объекта, которая получается с помощью компьютерной сети. Однако непосредственное применение оперативных данных, прошедших через компьютерную сеть со статистическим характером мультиплексирования, может иметь негативное влияние на качество управления в силу появления непредсказуемых задержек в контуре обратной связи. В этом случае даже простейшая задача стабилизации линейного динамического объекта превращается в весьма непростую задачу нелинейного стохастического управления.
С другой стороны, идея использования компьютерной сети для доступа к данным, поступающим в процессе функционирования объекта, представляется весьма привлекательной для создания распределенных систем управления в реальном времени. Хотя такие системы известны давно, но применение в качестве их среды универсальной инфраструктуры, например сети Интернет, позволяет говорить о появлении нового класса таких систем. Именно для них расширенная сетевая модель взаимодействия типа клиент¾ агент/сервер¾ объект (рис. 3) может найти эффективное применение.
Рис. 3. Многоуровневая модель межсетевого взаимодействия
По существу речь идет о создании нового класса управляемых технических систем, отличительной чертой которых является то, что в них в рамках процесса управления могут быть органически объединены как обработка информации и синтез управлений, так и передача управляющих воздействий. Использование возможностей высокоскоростных компьютерных телекоммуникаций позволяет применять в таких системах управления универсальные протоколы межсетевого взаимодействия и на этой основе интегрировать такие системы в универсальные информационно-управляющие инфраструктуры.
Принципы и проблемы построения универсальных информационно-управляющих инфраструктур.
Рассмотрим различные методы, алгоритмы и технические решения, нашедшие применение в построении систем интеллектуального управления сетевыми ресурсами.
1. Управление самоподобными сетевыми потоками в компьютерных сетях.
Использование компьютерных сетей в целях создания универсальных информационных и управляющих систем - одно из новых направлений развития теории и практики современных телекоммуникаций. Объединение различных информационных приложений с помощью сети Интернет предоставляет дополнительные возможности для создания интегрированной инфраструктуры передачи потоков данных. Проанализируем причины возникновения сложных процессов при передаче трафика в высокоскоростных компьютерных сетях и рассмотрим возможности использования свойств самоподобия автокорреляционной функции трафика для адаптации транспортных протоколов и прогнозирования состояния каналов связи.
Оценки характеристик трафика в современных сетях.
Для проведения количественного анализа характеристик трафика будем считать, что его структура полностью описывается последовательностью интервалов времени между передаваемыми пакетами. Поток пакетов считается ординарным, т.е. на выбранном интервале измерения может появиться только один пакет данных. Так как пакеты поступают неравномерно, то временной интервал между двумя последовательными приходами пакетов или группы пакетов является случайной величиной. Последовательность этих величин создает случайный поток событий {X
k}, на статистические характеристики и структуру которого воздействуют нескольких факторов:1) Специфика мультизадачных операционных систем с разделением времени.
2) Динамика работы информационного приложения, использующего средства межсетевого взаимодействия.
3) Реализация протокола транспортного уровня, обеспечивающего достоверную доставку пакетов и регулирование скорости их передачи с использованием замкнутого контура обратной связи между получателем и источником данных.
4) Особенности работы протоколов канального уровня.
5)
Характеристики и административные ограничения, введенные в промежуточных сетевых узлах с целью обеспечения заданных параметров качества сервиса.Рассмотрим эти факторы более подробно. Специфика работы мультизадачных операционных систем с разделением времени проявляется в том, что каждый работающий в системе процесс развивается в так называемом "виртуальном времени". Это время определяется работой планировщика задач и доступными ресурсами: оперативной памятью, загрузкой процессора, ограничениями на доступ к файловой системе. Отсюда следует, что в процессе передачи информации от уровня приложения до канального уровня, может возникнуть неравномерность интервалов времени между отдельными фазами формирования пакетов даже при условии их генерации в виде непрерывного потока данных.
Динамика работы самого приложения, использующего различные виды межсетевого обмена, также является важным фактором, определяющим характер агрегированного потока пакетов. В частности, приложение может генерировать данные с интенсивностью, определяемой внешним ресурсом (например, скоростью работы устройства внешней памяти или канала связи). Кроме того, большинство современных информационных приложений ориентированы на работу в архитектуре взаимодействия программных систем "клиент-сервер". В таких системах генерируется прерывистый поток данных, соответствующий логике работы прикладной системы, например,
WWW сервера [2].Большинство современных информационных приложений в сети Интернет построены на базе транспортного протокола, гарантирующего надежную доставку данных за счет контура обратной связи. Параметры этого контура значительно влияют на структуру потока данных, передаваемого на сетевом уровне. Например, транспортный протокол ТСР должен обеспечивать передачу пакетов без ошибок, используя для этого поток пакетов подтверждения и механизм ретрансмиссии потерянных пакетов. С точки зрения информационного приложения протокол ТСР формирует виртуальный канал, пропускная способность которого меняется во времени в зависимости от загрузки физических каналов передачи данных. Поэтому с позиций управления процессом передачи этот протокол функционирует как адаптивный регулятор, управляющий скоростью поступления пакетов в канал. Поскольку состояние сети определяется пропускной способностью канала и степенью заполнения буферов в промежуточных системах, то требуется адаптация транспортного протокола к текущему состоянию сети. Для этого осуществляется генерации пробных воздействий, которые реализуются с помощью алгоритмов так называемого "медленного старта" и "избегания перегрузки". В качестве параметра настройки используется размер окна перегрузки, с помощью которого регулируется число пакетов разрешенных к передаче в сеть до прихода пакетов подтверждения. В результате совместного влияния перечисленных выше факторов в виртуальном канале генерируется неравномерный поток пакетов [2]. Результирующий поток, генерируемый в моменты времени, связанные с приходом пакетов подтверждений может быть описан разностным уравнением:
Yk+1=F(Y,Xk,RTTk,Qk,Sk,g ),
(1)где F – нелинейная функция, зависящая от версии транспортного протокола, Y
k+1 - число пакетов, отправляемых в сеть при приходе пакетов подтверждения на (k+1) шаге работы протокола, Xk – текущий размер окна перегрузки , Qk - число пакетов подтверждения, RTTk - оценка времени пересылки пакета от источника к приемнику и обратно, Sk - вектор состояния транспортного протокола, соответствующего его описанию в форме конечного автомата, g - вектор параметров, который зависит от состояния виртуального соединения.Разностное уравнение (1) является основой для анализа свойств генерируемого потока. Его можно использовать для оценки взаимного влияния различных виртуальных соединений, которые передаются в одном физическом канале связи или сетевом сегменте и конкурируют за сетевые ресурсы.
В свою очередь, канальный уровень также может влиять на вариации временных зависимостей в трафике. Например, коллизии, возникающие при разделении общей среды передачи (протокол Ethernet), оказывают воздействия на временные интервалы между пакетами, которые увеличиваются при росте загрузки канала. Еще более сложные зависимости в потоках данных возникают при протоколов ATM и Frame Relay, которые имеют встроенные функции контроля качества виртуального соединения с помощью различных стратегий буферизации и приоритезации. Таким образом, в сети создается многоконтурная система регулирования скорости передачи пакетов, в которой внешний контур организован с помощью транспортного протокола, а характер переходных процессов зависит как от параметров сети, так и типа информационного приложения.
Статистическое агрегированние потоков.
Совокупность описанных выше факторов приводит к появлению ряда важных статистических свойств потока данных. Одно из таких свойств связано со сложной структурой трафика и проявляется в виде самоподобия его автокорреляционных функций. Это означает, что автокорреляционная функция r(k) потока {X
k} близка в том или ином смысле к автокорреляционной функции rm(k) агрегированного потока {Xk(m)}Можно дать строгое определение такого типа самоподобия стохастических процессов. Рассмотрим случайный процесс с постоянным математическим ожиданием m
= M{Xk}, ограниченной дисперсией s 2 =M{(Xk - m )2} <¥ и корреляционной функцией r(t) = M[(Xk - m )(Xk+t - m )] /s 2 , t = 0,1,2, .. Для агрегированного потока (2) автокорреляционная функция имеет вид:r(m)(t)= M [(Xk(m) - m )(Xk+t(m) - m )]/ M[(Xk(m) - m )2],
где t = 0,1,2,... ; m = 1,2,...
Процесс {X
k} называется самоподобным, если равенство r(m)(t) = r(t) (2) выполняется для любых значений t = 0,1,2,... и m = 1,2,... Таким образом, для самоподобных процессов автокоррелционная функция сохраняет свою структуру вне зависимости от параметра агрегирования потока m. Подобные свойства наблюдаются у так называемых фрактальных множеств, которые, в частности, образуют притягиваю множество или странный аттрактор траекторий хаотических динамических систем. Поэтому трафик в компьютерных сетях, обладающий свойством (3), называют фрактальным потоком, а в качестве их числовых характеристик будем использовать значения функции r(t) и оценку фрактальной размерности. Методы оценки параметров фрактальных потоков. Для описания параметров, характеризующих самоподобные свойства дискретных временных последовательностей, будем использовать понятия, введенные теории фрактальных множеств. Одной из главных отличительных особенностей таких множеств является их дробная размерность. Существует несколько способов определения такой размерности, однако наибольшее признание получило определение, предложенное Хаусдорфом [3]. Согласно этому определению фрактальная размерность D множества точек d-мерного пространства определяется соотношением: D =lim ln N(e
)/ln(1/e
) (3) , e
®
0
В результате корреляционная размерность определяется равенством
D2=-lim [logC(R)/log(R) ] (4).
e ® 0
Оценку фрактальных свойств временных последовательностей можно получить с помощью показателя Н Для его вычисления используются R/S статистика, которая определяется следующим образом. Так если {X
k}- множество последовательных значений некоторой физической величины, имеющее среднее значение m (k) = M{Xk} и дисперсию S2(k)=M(Xk- m (k))2], то R/S статистика задается выражением:R(k)/S(k) = [max{0,W1 ... Wk}- min{0,Wk1 ... Wk}]/S[k]
где W
k =(X1+X2+...+ Xk)- km (k).В результате показатель Херста
H определяется путем аппроксимации полученной зависимости с помощью соотношения:H = argmin{M [R(k)/S(k)]- a kH ] }2 (5).
Для вычисления
H можно использовать зависимость "дисперсия- время". Для этого исходная последовательность {Xk} разбивается на непересекающиеся последовательные блоки размера m, каждому из которых сопоставляется величина (2). Для полученной последовательности X(m) вычисляется значение s 2(m)=M{(X(m)k- m )2}и строится зависимость Log(s 2(m)) как функция от Log(m). усредненный угловой наклон b этой зависимости связан с показателем Херста соотношением b =2(H- 1). Численные значения H, b ,D2 имеют различные интерпретации. Для большинства стандартных моделей потоков, например, для пуассоновского значение H = 0.5 , а b = - 1. В случае, когда 0.5 < H < 1.0 принято говорить о процессах с сильной корреляционной связанностью, которая в частности может проявляться в самоподобии автокорреляционной функции. Таким образом, фрактальность потока, наличие показателя Херста в диапазоне 0.5 < H < 1.0 и самоподобие автокорреляционной функции являются тесно связанными свойствами.2. Применение свойств самоподобия трафика для прогнозирования и управления.
Изучение статистических характеристик позволяет получить дополнительные сведения для решения задач сетевого управления. Например, в случае наблюдения выраженных признаков самоподобия в агрегированном потоке ( рис. 4), возможна оценка состояния r(k), где k -дискретное время процесса во временной области.
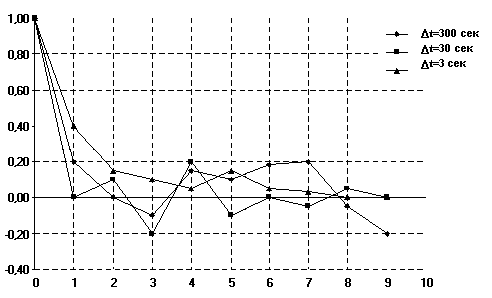
Рис. 4. Автокорреляционная функция, построенная для интервалов дискретизации потока пакетов в 3 сек, 30 сек и 300 сек.
Для выполнения среднеквадратического прогноза на s шагов вперед, можно вычислить значение y
t+s в виде линейной комбинацииt
y t+s =S h(t+s,k)y k (6).
k=0
В этом выражении коэффициенты h
k находятся из условия минимума ошибки прогнозирования:J2= M {(yt+s - yt+s) }® min (7).
Итоговый результат прогноза задается формулой
y t+s = Rtr(t,s)y t, (8),
где r
(t,s)=M{yt+syt), Rt=M{ytyt},причем величина прогноза по временной шкале определяется исходя из масштабного коэффициента m, который используется при вычисления самоподобной автокорреляционной функции r(t,s).Такая масштабируемость прогноза позволяет на основе результатов измерения ограниченного набора данных получать оценки для широкого диапазона временных интервалов.
В качестве примера возможного применения такого прогнозирования, рассмотрим систему, обслуживающую потоки данных нескольких классов. В качестве такой системы может выступать устройство доступа в сеть ATM. Пусть на входе системы имеется несколько виртуальных каналов, часть из которых передает трафик с наивысшим приоритетом (классы CBR и VBR), а часть - низкоприоритетный трафик (классы ABR и UBR). Если пропускная способность выходного канала системы меньше суммы входных, то происходит конкуренция за ресурс
– передача более приоритетного трафика за счет менее приоритетного. Предсказание во временной области изменения значения потоков, проходящих через это устройство, может позволить:1) Динамически перераспределять размеры буферов, компенсируя недостаток пропускной способности, выделенный для низкоприоритетных данных.
2) Обеспечивать оптимальные временные характеристики, например задержку при буферизации, для VBR потоков.
3) Формировать локальные контуры управления перегрузкой буферов и каналов связи ATM сети.
4) Дать возможность источникам, передающим данные с помощью транспортного протокола с обратной связью (TCP), получать прогнозы доступной пропускной способности сети и соответственно модифицировать стратегии избегания перегрузок.
Для этих задач весьма эффективно можно использовать реализацию алгоритмов адаптации и управления с помощью самонастраивающихся сетевых компонент, получивших название интеллектуальных агентов. В этом случае передача данных и выработка управляющих воздействий не формируется в одном программном модуле, а локализуется в том месте сетевой инфраструктуры, в котором соответствующие задачи могут быть решены с привлечением минимальных сетевых ресурсов.
Таким образом, анализ фрактальных свойств трафика позволяет выделить важные числовые характеристики, на основе которых могут быть построены адаптивные алгоритмы статистического управления и прогнозирования. В результате использование свойств самоподобия автокорреляционной функции трафика можно обеспечить достижение высокой степени масштабируемости прогноза, что в свою очередь позволяет получать оценки для широкого диапазона временных интервалов на основе результатов измерения ограниченного набора данных.
3. Методы хранения данных для систем управления сетевыми ресурсами.
При решении задач управления сетевыми ресурсами встает задача накопления статистических и оперативных данных о состоянии различных компонент компьютерной сети для последующего анализа и принятия решений по изменению управляющих воздействий для выхода системы из критических ситуаций.
Для сбора информации для целей управления сетевыми ресурсами, в настоящее время применяется агентно-ориентированный подход.
Задача интеллектуальных SNMP агентов состоит в том, чтобы, используя стандартную распределенную базу данных MIB, распознать ситуацию, которая может приводить к неисправности или вообще к некорректной работе сети. Для этой цели применяются следующие методы:
а) сегментация данных
б) выделение характерных признаков
в) определение статистических свойств наблюдаемых данных
г) задание порогов предельно допустимых параметров
Для интеллектуальной системы управления сетевыми ресурсами недостаточны объемы и производительность как протокола SNMP, так и неудобство работы с MIB.
MIB сама по себе имеет некоторую структуризацию переменных, но для систем управления сетевыми ресурсами, ни такая (древовидная) структуризация, ни возможность содержать таблицы переменных оказывается недостаточной. Для распознавания критических ситуаций и принятия решений по каждой из них требуется гораздо больший объем хранимой информации. Из-за развития технологий хранения данных уменьшились, а в ряде случаев, отпали, проблемы с накоплением и хранением больших объемов информации. Основная проблема возникла при необходимости использовать эти колоссальные объемы для поддержки принятия решений в системах управления (например, сетевыми ресурсами).
При возникновении баз данных считалось, что они откроют широкие возможности для построения систем поддержки принятия решений. Однако развитие этого направления привело к тому, что они в первую очередь ориентировались на решение операционных (рутинных) задач, а не на поддержку принятия решений.
В начале 90-х годов стало очевидно, что для создания распределенных систем сетевого управления помимо традиционной (по запросам), требуется аналитическая обработка данных.
Традиционные (операционные) базы данных оказались мало пригодны для решения задач аналитической обработки по следующим причинам:
а) физическое различие между объектами, на которые направлена операционная структура, и объектами, необходимыми для анализа, планирования и принятия решений
б) технологии обеспечения операционной обработки фундаментально отличаются от технологий поддержки принятия решений
в) характер запросов пользователей, обслуживающих операционистские системы, совершенно иной, чем характер запросов систем управления.
В связи с этим широкое распространение получили программы предварительной обработки данных, позволяющие агрегировать различные выборки данных из основной базы в дополнительные.
Это позволяет преодолеть недостатки, связанные с:
а) недостоверностью (возникает из-за отсутствия меток времени, различия в алгоритмах подготовки данных, различные источники данных)
б) низкой производительностью при нестандартных запросах
в) невозможностью преобразования разнородных данных в единую информацию
Предварительная обработка позволяет:
а) найти, где находятся необходимые данные
б) обработать и проанализировать данные
в) привлечь дополнительные (специализированные) ресурсы для решения аналитических и управленческих задач
В сети может существовать множество наборов данных, содержащих различные по названиям, но одинаковые, по сути, элементы. Таким образом, чтобы обработать эти данные, необходимы программы извлечения данных для каждого источника данных, каждая программа должна согласовывать форматы данных с другими программами и т.п. Подготовка такой технологической цепочки под каждый запрос приводит к недопустимому времени формирования запроса.
Для преодоления этих недостатков возникла концепция единого источника данных -
Data WarehouseData Warehouse
– это предметно-ориентированная (subject-oriented), интегрированная (integrated), некорректируемая (nonvolatile), зависимая от времени (time-variant) коллекция данных, предназначенная для поддержки принятия управленческих решений.Хранилище данных должно сформировать такую среду накопления данных, которая оптимизирована для сложных аналитических запросов, связанных с признаками состояния. Эти запросы могут быть достаточно индивидуальны для каждой системы, линии и узла сети.
Хранилище данных должно автоматически собирать операционные данные, согласовывать их и объединять в предметно-ориентированный формат, который нужен интеллектуальным анализирующим системам. Данные в хранилище данных не предназначены для модификации.
Предметная ориентация означает, что данные объединены в категории и хранятся в соответствии с теми областями, которые они описывают, а не с приложениями, в которые они используются.
Интегрированность определяет данные сразу таким образом, чтобы они удовлетворяли требованиям всей системе управления, а не единственной ее функции. Тем самым хранилище данных гарантирует, что одинаковые ответы, сгенерированные для разных агентов будут содержать одинаковые результаты.
Некорректируемость заключается в том, что данные в хранилище данных не создаются (они поступают непосредственно от агентов), не корректируются и не удаляются.
Зависимость от времени подразумевает, что хранилище данных предназначено для анализа данных во времени. Важно знать не только значения данных, но и время их появления. Кроме того, данные в хранилище данных должны быть согласованы во времени. Нельзя допустить, чтобы данные из различных источников считывались по состоянию на разные моменты времени.
Направленность на принятие управленческих решений гарантирует правильное использование хранилища данных для анализа и поддержки принятия решений, а не для обработки транзакций.
4. Средства интеллектуального извлечения
Существует пять стандартных типов закономерностей, которые позволяют выявлять интеллектуальные методы анализа и представления данных:
Ассоциация
Последовательность
Классификация
Кластеризация
Прогнозирование
Ассоциация проявляется в случаях связи нескольких событий друг с другом.
Последовательность – цепочка связанных во времени событий.
Классификация – выделение признаков, характеризующих группу, к которой принадлежит объект. Это делается посредством анализа уже классифицированных объектов и формулирования некоторого набора правил.
Кластеризация – аналогична классификации, но отличается отсутствием четко сформированных групп.
Прогнозирование – на основе особенностей поведения данных оцениваются будущие значения непрерывно изменяющихся переменных
Существуют четыре основных интеллектуальных средства анализа данных:
Нейронные сети
Деревья решений
Индукция правил
Визуализация данных
Нейронные сети – совокупность связанных друг с другом узлов, получающих входные данные, осуществляющих их обработку и генерирующих на выходе некоторый результат. Между узлами видимых входного и выходного уровней может находиться несколько уровней скрытой обработки. Такая сеть способна обучаться. Имеется специальный набор данных, совокупность входных значений которых порождает заранее установленное множество выходных. Для каждого сочетания обучающих данных на входе выходные значения сравниваются с известным результатом. Если они отличаются, то вычисляется корректирующее воздействие, учитываемое при обработке в узлах сети. Указанные шаги повторяются, пока не выполнится условие "останов", например необходимая коррекция не будет превышать некоторой величины.
Нейронные сети реализуют непрозрачный процесс. То есть, построенная таким образом модель не имеет четкой интерпретации.
Деревья решений разбивают данные на группы на основе значений тех или иных переменных. Далее задаются вопросы, в результате которых образуется иерархия операторов "если-то", которые и классифицируют данные.
Алгоритмы, применяющие деревья решений работают в целом быстрее нейронных сетей, но для некоторых типов данных они могут оказаться неприемлемыми. Так в случае неаккуратного ранжирования данных может оказаться, что если какой-либо параметр испытывает существенный разрыв, то он может оказаться скрытым. Эта проблема часто решается путем применения нечеткой логики для разбиения на группы.
Визуализация данных, строго говоря, не является средством анализа информации, поскольку только представляет информацию пользователю. Тем не менее, визуальное представление сразу нескольких переменных может достаточно выразительно обобщить значительные объемы данных.
Данные для системы удобно представлять в многоразмерных базах данных ("гиперкубах"), где в качестве размерностей выступают такие интересующие аналитическую систему атрибуты, как время, объем трафика, количество ошибок и т.п. В связи с тем, что представление базы данных в многоразмерном виде на физическом уровне требует значительных затрат памяти, производители инструментальных средств для создания систем поддержки принятия решений используют различные способы для работы с данными. (Данные хранятся в реляционном виде, но имитируют многоразмерность для пользователя; многоразмерные базы; как многоразмерные базы, так и реляционный вид).
Data Mining – интеллектуальное извлечение информации.
Помимо извлечения данных из операционных баз для принятия решений весьма актуален процесс интеллектуального извлечения знаний (data mining) в соответствии с информационными потребностями системы. Тема извлечения знаний не нова для искусственного интеллекта. Она является основой для наполнения базы знаний экспертной системы. Однако в экспертных системах основное внимание уделялось проблеме получения знаний от экспертов, а не из хранилища или базы данных. Очень актуальна проблема извлечения знаний для целей управления в компьютерных сетях с помощью интеллектуальных средств.
С точки зрения пользователя в процессе извлечения знаний должны решаться следующие задачи преобразования:
Данные (неструктурированный набор чисел и символов) в информацию (описание обнаруженных закономерностей)
Информации в знания (значимые для пользователя закономерности)
Знаний в решения (последовательность шагов, направленная на достижение потребностей пользователя)
Интеллектуальные средства извлечения информации позволяют почерпнуть из хранилища намного более глубокие сведения, чем традиционные системы оперативной обработки транзакций (OLTP) и оперативной аналитической обработки (OLAP). Такие инструменты поиска и анализа выявляют закономерности и выводят из них правила. Эти закономерности и правила можно использовать для принятия решений и прогнозирования их последствий. Кроме того, подобные средства способны ускорять анализ за счет акцентирования внимания на самых важных переменных.
5. Нейронные сети
Это большой класс разнообразных систем, чья архитектура в некоторой степени имитирует построение нервной ткани из нейронов. В одной из наиболее распространенных архитектур, многослойном персептроне с обратным распространением ошибки, эмулируется работа нейронов в составе иерархической сети, где каждый нейрон более высокого уровня соединен своими входами с выходами нейронов нижележащего слоя. На нейроны самого нижнего слоя подаются значения входных параметров, на основе которых нужно принимать какие-то решения, прогнозировать развитие ситуации и т. д. Эти значения рассматриваются как сигналы, передающиеся в вышележащий слой, ослабляясь или усиливаясь в зависимости от числовых значений (весов), приписываемых межнейронным связям. В результате этого на выходе нейрона самого верхнего слоя вырабатывается некоторое значение, которое рассматривается как ответ, реакция всей сети на введенные значения входных параметров. Для того чтобы сеть можно было применять в дальнейшем, ее прежде надо "натренировать" на полученных ранее данных, для которых известны и значения входных параметров, и правильные ответы на них. Эта тренировка состоит в подборе весов межнейронных связей, обеспечивающих наибольшую близость ответов сети к известным правильным ответам. Такой подход нашел применение в задачах прогнозирования, к сожалению, методика подбора параметров прогнозирования требует значительных интеллектуальных затрат. Кроме того, многослойный персептрон фактически не применим для задач кластеризации, как принципиально обучаемый "с учителем", т.е. для его настройки требуется уже сформированная система категорий.
6. Самоорганизующиеся карты.
Применение самоорганизующихся карт для исследовательского анализа данных.
Data Mining, иногда также называемый обнаружением знаний в базе данных, соответствует процессу извлечения новейших, потенциально полезных знаний из обширного множества данных, посредством чего знания могут исследоваться в интерактивном режиме. В статистике data mining также называется исследовательским анализом данных. Для начала какой-либо метод используется для выделения структур в наборе данных. Более точные цели устанавливаются, основываясь на выделенных структурах, и, наконец, некоторый дополнительный статистический метод может использоваться для подтверждения результатов.
Центральной целью в исследовательском анализе данных является представление набора данных в форме, которая наиболее просто воспринимаема, но в то же время сохраняет столько определяющей информации, сколько возможно. Методы исследовательского анализа данных - это инструменты общего назначения, которые выделяют существенные особенности множества данных, такие как кластерная структура и отношения между самими элементами данных.
Можно различить две категории инструментов исследовательского анализа данных с несколько различными целями. Во-первых, некоторые инструменты, такие как проекции Саммона отображают многоразмерные массивы данных в, например, двумерную плоскость при попытке сохранить его полную структуру (дистанцию между элементами данных), так хорошо, как это возможно. Другие методы пытаются найти кластеры данных, посредством чего вместо больших массивов данных образуется только некоторое число кластеров, нуждающихся в рассмотрении.
Доступно обширное число различных алгоритмов, выполняющих кластеризацию. Выбор подходящих алгоритмов и их правильное применение требует обширных знаний как алгоритмов, так и множества данных. В наборе данных должна существовать достаточная тенденция к кластеризации, чтобы использование алгоритмов кластеризации было бы вообще чувствительным, и поскольку различные алгоритмы кластеризации имеют тенденцию находить кластеры различных видов, пригодность этих видов для описания набора данных должна проверятся.
С другой стороны, метод проекций, не уменьшает количество данных для представления. Хотя они выделяют и показывают существенные особенности множества данных, эта иллюстрация сложна в получении и может все еще быть трудна для понимания, если массив данных велик.
Алгоритмы SOM это уникальный метод, в котором комбинируются задачи как проекционных, так и кластерных алгоритмов. Он может быть использован, в одно и тоже время, для визуализации кластеров во множестве данных и для представления множества на двумерной карте способом, который сохраняет нелинейные отношения элементов данных; близлежащие элементы расположены на карте ближе друг к другу. Кроме того, если не существует явных кластеров во множестве данных, метод SOM обнаружит "ущелья" и "хребты", то есть открытые области с нерегулярными формами и высокой кластерной тенденцией, принимая во внимание, что этот алгоритм отделяет поднаборы данных, которые имеют различную статистическую природу.
Самоорганизующиеся карты Кохонена (SOM) обладают благоприятным свойством сохранения топологии, которое воспроизводит важный аспект карт признаков в коре головного мозга высокоорганизованных животных. В отображении с сохранением топологии близкие входные примеры возбуждают близкие выходные элементы. По существу SOM представляет собой двумерный массив элементов, причем каждый элемент связан со всеми n входными узлами. Такая сеть является специальным случаем сети, обучающейся методом соревнования, в которой определяется пространственная окрестность для каждого выходного элемента. Локальная окрестность может быть квадратом, прямоугольником или окружностью. Начальный размер окрестности часто устанавливается в пределах от 1/2 до 2/3 размера сети и сокращается согласно определенному закону (например, по экспоненциально убывающей зависимости). Во время обучения модифицируются все веса, связанные с победителем и его соседними элементами.
Самоорганизующиеся карты Кохонена могут быть использованы для проектирования многомерных данных, аппроксимации плотности и кластеризации. Эта сеть успешно применялась для распознавания речи, обработки изображений, в робототехнике и в задачах управления.
Параметры сети включают в себя размерность массива нейронов, число нейронов в каждом измерении, форму окрестности, закон сжатия окрестности и скорость обучения.
Формально SOM могут быть описаны как нелинейное, упорядоченное, однородное отображение высокоразмерных входных доменов данных в элементы регулярного низкоразмерного массива. Это отображение выполняется следующим образом. Примем, что множество входных переменных
|
|
(1)
|
Наша задача – определить
Можно попытаться определить
|
|
(2)
|
Где
Множество значений
|
|
(3) |
Определяет порядок значений
К сожалению, минимизация (3), даже в наиболее фундаментальных случаях, еще не решена в точном виде, и алгоритмы, пытающиеся сделать это точно, оказываются слишком сложными для практического применения. Хотя так называемая стохастическая аппроксимация минимизации
|
|
(4) |
Тогда алгоритм оптимизации есть:
|
|
(5) |
Где
Множество различных SOM алгоритмов может быть представлены формулой (5). Например, если
|
|
(6) |
Здесь
![]()
Мы можем выразить более простое SOM уравнение как
|
|
(7) |
Далее SOM алгоритм может быть упрощен следующим образом. В пределе сходимости каждый
|
|
(8) |
Здесь
|
|
(9) |
Где
Шаги обучения определяются следующим образом:
1. Для начального кодового вектора
2. Для каждого элемента карты
3. Взять в качестве нового значение каждого нового кодового вектора среднее по соответствующему списку.
Повторить с шага 2 несколько раз.
Разработка системы хранения данных на базе технологий хранилищ данных и поддержки принятия решений (исследовательского анализа данных) на базе методов и алгоритмов нейронных сетей, в частности самоорганизующихся карт, позволит значительно повысить эффективность работы системы управления сетевыми ресурсами за счет повышения оптимальности запросов, а, следовательно, скорости их обработки и, в результате, скорости и эффективности работы системы управления в целом. В совокупности с подсистемой поддержки принятия решений на базе технологий самоорганизующихся карт, система управления сетевыми ресурсами явится эффективным средством поддержки больших компьютерных сетей.
Реализация экспериментальной универсальной информационно-управляющий инфраструктуры.
Изложенные выше соображения и подходы были использованы для создания сетевой системы управления манипулятором, созданным в ЦНИИ РТК для космического корабля "Буран". Работы начались в августе 1996 года и были закончены в октябре. Комплексная демонстрация возможностей системы состоялась в Турине (Италия) в октябре 1997 года на специализированной выставке космической техники, приуроченной к 48-му конгрессу IAF (международная федерация астронавтики).
В процессе выбора программно-аппаратного комплекса для управления манипулятором через сеть INTERNET обсуждались две возможности ¾ создание специализированных приложений или использование уже существующих стандартных протоколов и программных продуктов. Для решения проблемы удаленного управления был избран второй подход.
Для создания "пульта оператора" требовалось найти универсальную, т.е. работающую на любой аппаратной платформе программу, обеспечивающую интерактивное взаимодействие оператора и объекта управления. В качестве такой программы было решено использовать
WEB-браузер. Основное требование к нему ¾ это возможность работы с фреймами, формами и битовыми картами. Такой выбор значительно упростил дальнейшую работу над интерфейсом системы, поскольку для формирования управления на стороне оператора было необходимо произвести простые операции. Все необходимые вычисления и логические операции по координации движения производились на WEB-сервере, расположенном в Санкт-Петербурге. Однако свойства используемого протокола HTTP/1.0 позволяли инициировать обмен информацией только со стороны клиента. При разработке интерфейса для пульта оператора был проведен анализ возможности применения языка Java. Однако от него пришлось отказаться, поскольку полученные программные модули могли работать не на всех платформах и не вносили никакой дополнительной функциональности.Значительные трудности представлял также выбор программ и оборудования для передачи видео- и аудиосигнала. В результате анализа выбор был сделан в пользу комплекса программ
VIC+VAT+WB и системы видеоконференций ShowMe для компьютеров фирмы SUN.Созданный программно-аппаратный комплекс управления манипулятором выглядел следующим образом:
Специализированная ЭВМ, управляющая манипулятором, связана интерфейсом RS 232 с компьютером IBM PC, работающим под управлением операционной системы Linux. На этом компьютере был запущен
WEB-сервер Apache, который осуществляет взаимодействие с браузером пользователя.Интерфейс пульта оператора был реализован с помощью стандартных возможностей языка HTML 3.0. Обработка информации и взаимодействие со специализированной ЭВМ осуществлялось с помощью CGI-подпрограмм, написанных на языке C. В этой же машине были установлены два устройства frame grabber Matrox Meteor, что позволяло одновременно передавать видеоизображение с двух телекамер.
Следующей технической проблемой являлась интеграция комплекса с сетевой инфраструктурой, которая в эксперименте была представлена сетью ATM. Пришлось отказаться от использования ATM-адаптера непосредственно в управляющей машине. ATM-канал заканчивался в компьютере SUN Sparс 20, который выполнял роль маршрутизатора между интерфейсами ATM и сегментов локальной сети Ethernet.
Получение ATM-канала необходимой пропускной способности и заданного качества (PVC) через территорию Европы оставалось главной проблемой, которая была решена с участием европейских телекоммуникационных компаний. Созданный в результате ATM-канал был проложен через территорию Финляндии и далее через европейскую исследовательскую АТМ сеть JAMES.
Пульт оператора на выставке в Турине представлял собой мультимедийный компьютер с полиэкранной оболочкой. В одном из окон оператор видел собственное изображение, в двух других ¾ переключаемое изображение с трех камер, установленных на манипуляторе, рядом с ним и в кабине управления. После заполнения координат цели и других параметров движения оператор нажимал кнопку "старт", моделируемую средствами
WEB-браузера, и видел в других окнах общий вид перемещающегося манипулятора и вид из камеры, установленной на схвате манипулятора. При соответствующем переключении камер и включении необходимого программного обеспечения имелась дополнительная возможность проводить телеконференции между специалистами Италии и России для решения технических проблем и для ответов на вопросы.Проведенный эксперимент наглядно показал новые возможности применения сетевых технологий для теории и техники. Вместе с тем полученные в ходе эксперимента результаты позволили сформулировать, а затем и реализовать новую концепцию сетевого процессора.
Концепция многофункционального сетевого процессора для управления в компьютерных сетях на основе интеллектуального извлечения информации.
Основные концептуальные требования к изделию
На основании главных концептуальных требований, которые отражают характеристики не одного изделия, а целого семейства, в дальнейшем можно сформулировать технические требования для конкретного устройства, исходя из потребностей к его производительности, количеству обслуживаемых каналов связи и их максимальной пропускной способности, требований к себестоимости изделия и условий его работы.
Основными концептуальными требованиями к изделию будут:
Многофункциональность
Сетевой процессор должен обеспечить возможность перестройки своих основных функциональных программно-аппаратных характеристик по желанию обслуживающего его сетевого администратора. Это означает, что набор входящих в его программное обеспечение модулей должен допускать их оперативную замену и настройку, а набор сетевых интерфейсов должен допускать возможность выбора не только их количественного состава, но и типа (
Ethernet, ATM, последовательный порт и т.д.).Эффективность
Применение сетевого процессора при построении ЛВС должно повысить эффективность действующего сетевого оборудования, каналов связи и рабочих станций сети, что приведет к повышению качества предоставляемого сетью сервиса, а значит и защите вложенных в развитие сетевой технологии инвестиций.
Защита информации
В качестве одной из характеристик сетевого процессора должна быть функция обеспечения защиты передаваемой по контролируемой сети информации. Для этого должна быть возможность использования криптографические методы, а также методы построения виртуальных локальных сетей.
Управление трафиком
В состав программного обеспечения сетевого процессора должна быть заложена возможность регулирования пропускной способности виртуальных каналов связи и управления пакетным трафиком в сетях на основе технологий интеллектуальной коммутации и маршрутизации.
Виртуальные сети
В набор функциональных характеристик должна входить возможность построения виртуальных локальных сетей на основе информации канального, сетевого, транспортного и прикладного уровней.
Открытая архитектура ПО
Сетевой администратор должен иметь возможность перезагрузки программного обеспечения сетевого процессора и его переконфигурации в соответствии с текущими потребностями с удаленного компьютера посредством управляющей диалоговой программы. Для обеспечения этой возможности создаваемое устройство должно иметь специальный аппаратный связной интерфейс.
Масштабируемость
Принципы построения аппаратно-программной основы сетевого процессора должны обеспечить возможность обслуживания возрастающего сетевого трафика и количества обслуживаемых виртуальных сетей без изменения концепции управления, заложенной сетевым администратором.
Техническая реализация сетевого процессора.
В качестве проверки основных положений изложенной концепции многофункционального сетевого процессора, в лаборатории № 329 разработан прототип такого устройства (опытный образец изделия)
Планируемая область применения:
В качестве аппаратной базы устройства была выбрана одноплатная бездисковая ЭВМ, имеющая в составе:
CPU Intel P133
RAM 4 Mb
Flash 4 Mb
COM Com1, Com2 (RS-232)
Ethernet-card 2
шт. и болееWatch-Dog Timer 1
Устройство выполнено в малогабаритном промышленном корпусе и рассчитано на работу в следующих климатических условиях:
Температура окружающего воздуха от 0 до +35С
Относительная влажность воздуха при 35С от 40% до 98%
Программное обеспечение сетевого процессора реализовано на основе ядра 32-х разрядной операционной системы реального времени
QNX-4.23A в виде набора программных модулей, которые в совокупности обеспечивают следующие функциональные характеристики устройства:Управление и контроль за работой сетевого процессора обеспечивается со станции удаленного контроля, в качестве которой может использоваться любой персональный компьютер, работающий под управлением операционной системы
Windows3.1/95 или OS/2.Созданная управляющая программа предоставляет следующие функциональные возможности системному администратору:
Опытный образец многофункционального сетевого процессора демонстрировался на ряде выставок, в том числе:
Выставка министерства науки РФ – "Достижения ГНЦ в 1997г.", СПб, июнь 1997г.
Выставка министерства обороны РФ – "Модуль-97", Москва, октябрь 1997г.
Демонстрация опытных образцов изделия показала большую заинтересованность в изделиях подобного типа у представителей как государственных, так и коммерческих организаций, использующих сетевые технологии, приложения Интернет и средства защиты информации в корпоративных сетях.
Список литературы
1.Заборовский В.С., Лопота В.А., Шеманин Ю.А. Архитектура интеллектуальной информационной инфраструктуры высокоскоростных компьютерных сетей // Конверсия¢95, № 11, 1995. с.12-14.
2. Заборовский В.С. Интеллектуальные системы управления информационными ресурсами в высокоскоростных телекоммуникационных сетях // Тезисы докл., III Междунар. научно-методич. конф. "Высокие интеллектуальные технологии образования и науки" / СПбГТУ. СПб, 1996. с.19.
3. K. Park, G. Kim, M. Crovella, "On the effect of traffic self-similarity on network performance", in Proc. of the 1997 SPIE International Conference on Performance and Control of Network Systems.
4. L. Kalampoukas, A. Varma and K. K. Ramakrishnan, "Two-Way TCP Traffic over ATM: Effects and Analysis", in Proceedings of IEEE INFOCOM'97, Kobe, Japan, April 1997.
5. Г. Шустер , "Детерминированный хаос. Введение ", - М.: Мир, 1988 - 240с. пер. с англ.
6. T. Kohonen "The Self-Organizing Map" in Triennial Report of NNRC & LCIS Helsinki University of Technology, Otaniemi, 1997
7. S. Kaski, T. Kohonen "Statistical Data Analysis by the Self-Organizing Map" in Triennial Report of NNRC & LCIS Helsinki University of Technology, Otaniemi, 1997
8. Попов Э.В. и др. Статические и динамические экспертные системы.- М.: Финансы и статистика, 1996. – 318 с.
9. Едельштайн Н. Интеллектуальные средства анализа, интерпретации и представления данных в информационных хранилищах // Компутеруик. - 1996. №16.
10. Зельцер А. Информационные хранилища в сетях предприятий // Компутеруик. - 1995. №12.
11. Сахаров А.А. Концепции построения и реализации информационных систем, ориентированных на анализ данных // СУБД. - 1996. №4.