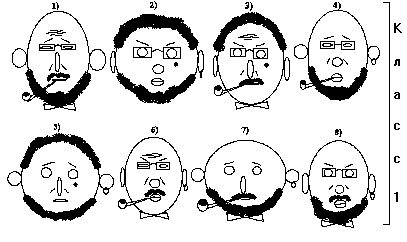
Формирование знаний в системах искусственного интеллекта: геометрический подход
(Доклад приведен в сокращенном варианте, с полным текстом можно ознакомиться в оригинал - макете журнала)
В настоящее время развитие искусственного интеллекта (ИИ) определяется тремя парадигмами. Первая связана с архитектурными решениями на основе параллельных и асинхронно протекающих процессов, перемещающихся по структуре взаимосвязанных однотипных компьютеров. Разработка теории таких процессов - одна из центральных проблем ИИ.
Вторая парадигма ИИ - когнитивная компьютерная графика, представляющая собой эффективных технический инструмент воздействия на интуитивное образное мышление исследователя.Функция когнитивной графики заключается в наглядном изображении внутреннего содержания предмета, которым может быть, в частности, любое абстрактное научное понятие, гипотеза или теория. Динамизм компьютерной графики, отсутствие принципиальных ограничений на форму, характер и структуру изображений, за которыми может стоять мощный вычислительный эксперимент, использование дополнительных цветовых и музыкальных эффектов (мультимедиа) открывает "правополушарные" каналы связи между исследователем и интересующей его проблемой.
Третья парадигма состоит в создании гибридных интеллектуальных систем обеспечивающих пользователю комфортное взаимодействие с пакетами прикладных программ и делающих доступной для него многогранную область вычислительной математики.
Актуализация отмеченных парадигм во многом обусловлена экстенсивным увеличением технических возможностей современных компьютеров. В то же время "узким" местом ИИ, в меньшей степени зависящим от наращивания технических мускулов, была и остается проблема получения и манипулирования знаниями, которые составляют основу любой интеллектуальной системы. Эта проблема имеет глубинные корни и затрагивает все без исключения аспекты ИИ.
При решении проблемы получения знаний выделяют три стратегии [1]: приобретение знаний, извлечение знаний и формирование знаний.
Термин "формирование" знаний связывают с созданием компьютерных систем, реализующих методы автоматического получения знания, так называемые методы "машинного обучения" (machine learning).
На сегодняшний день это наиболее перспективное направление инженерии знаний, предполагающее, что в результате автоматизации процесса обучения система "сможет" самостоятельно сформировать необходимые знания на основе имеющегося эмпирического материала (данных).
В настоящее время специалистам стало ясно, что инженер по знаниям с помощью одного лишь диалога с экспертом в какой-то конкретной области не способен добыть все нужные для разработки интеллектуальной системы сведения. Требуется еще и множество примеров, на которых удастся обучить машину [2].
В самом общем виде формирование знаний - это задача обработки баз данных (БД) с целью перехода к базам знаний (БЗ). В БД накапливаются и хранятся эмпирические факты из исследуемой предметной области (фактические данные, примеры экспертных заключений, элементарные высказывания с некоторой оценкой и т.п.), представленные в виде троек <объект-признак-значение признака>.
В БЗ заносятся сведения, выражающие закономерности структуры множества эмпирических фактов, релевантные прикладному контексту. Контекст определяет отношения между объектами из БД. Он может задаваться извне БД (например экспертом) и также продуцироваться признаком или совокупностью признаков из БД.
Чаще всего на практике встречаются отношения эквивалентности и порядка. Отношения эквивалентности присущи, в частности, задачам классификации, диагностики и распознавания образов. Отношения порядка свойственны задачам шкалирования, прогнозирования и т.п.
Ниже пойдет речь в основном об отношениях эквивалентности. Методы формирования знаний имеют много общего с методами решения упомянутых задач классификации, диагностики и распознавания образов. Но их одной из главных отличительных черт является функция интерпретации закономерностей, кладущихся в основу правил вхождения объектов в классы эквивалентности. Именно поэтому в инженерии знаний наибольшее распространение получили логические методы, например, "эмпирического предсказания" [3], "индуктивного формирования понятий" [4,5], "построения квазиаксиоматической теории" [6] и др.
Есть еще одна важная причина, обусловившая приоритет логических методов. Она заключается в сложной системной организации областей, являющихся прерогативой искусственного интеллекта. Эти области относятся, как правило, к надкибернетическому уровню организации систем [3], закономерности которого не могут быть достаточно точно описаны на языке статистических или иных аналитических математических моделей [4]. Гибкость и многообразие логических конструкций индуктивного вывода позволяют нередко добиваться успешных результатов при описании таких сложных систем.
В то же время главной проблемой создания таких конструкций остается проблема перебора большого количества вариантов. При этом отмечается, что совершенно не ясно, как можно распараллелить символьную операцию логического вывода. Отсюда применение логических методов часто вынуждено опираться на эвристические соображения, не имеющие строго обоснования.
Альтернативу логическим символьным методам составляет геометрический подход, переводящий задачу формирования знаний на язык геометрических соотношений между эмпирическими фактами, выступающими целостными информационными единицами и отображаемыми точками в пространстве признаков.
Это, с одной стороны, делает более понятными критерии и принципы построения правил вхождения объектов в определенные классы эквивалентности, которые основываются на сравнении объектов с помощью мер, имеющих интерпретацию расстояний.
С другой стороны, следует иметь в виду, что использование геометрического подхода при неограниченном расширении множества эмпирических фактов автоматически приводит к минимальным теоретически достижимым ошибкам принятия решений. Кроме того все операции легко распараллеливаются, а визуализация геометрической структуры множества точек позволяет организовать исследование закономерностей в совокупности эмпирических фактов средствами интерактивной когнитивной графики.
Более того, как будет показано ниже, можно получать наглядные визуальные представления о логических закономерностях в структуре данных - для этого применяется специальная локальная геометрия.Важность геометрического подхода к решению задач искусственного интеллекта подчеркивается в [9]. В отличие от символьных логических методов, реализующих операции над признаками в геометрическом подходе главными элементами выступают объекты, а основным видом операций является операция определения расстояния между объектами в многомерном пространстве признаков.
Геометрический и логический подходы составляют оппозицию, которой соответствует ряд других оппозиций: конкретное-абстрактное, параллельное-последовательное, синтез-анализ, безусловное-условное, экстенсиональное-интенсиональное представление знаний, интуитивное-рациональное, правополушарный-левополушарный механизмы мышления и т.п.
В то же время внутри указанных оппозиций имеется тесная связь. Она выражается в том, что "конкретное одновременно воплощает и абстрактную сущность его, сопричаствует с ним; конкретное - всего лишь знак отвлеченного и всеобщего" [10].
Так, например, любой конкретный объект есть конъюнкция элементарных событий, представляющих собой попадание значений признаков в определенные интервалы. Или, в частности, классификатор, действующий по принципу минимума расстояния, эквивалентен линейному решающему правилу [11], являющемуся формой интенсионального представления знаний.
Главная проблема геометрического подхода состоит в поиске ответа на вопрос, какие признаки и какую меру следует выбрать для определения расстояний между объектами. В известных методах анализа данных эта задача формулируется как подбор взвешенной метрики с использованием обучающей и частично обучающей информации [12] или как оцифровка переменных, основанная на максимизации статистического критерия [13].
Удачное решение указанной задачи геометрически выражается расширением "сферы действия" объектов, выступающих в роли представителей своих классов эквивалентности [14]. Однако методы решения данной задачи в инженерии знаний имеют свои существенные особенности.
Традиционные методы анализа многомерных данных, опирающиеся на геометрическую метафору, используют представление об общем пространстве признаков для всех объектов и об одинаковой мере, применяемой для оценки их сходства или различия. Такое представление уместно, например, при изучении однородных физических феноменов на статистическом уровне системной организации, в которых объект можно рассматривать как реализацию многомерной случайной величины с ясным физическим смыслом, когда есть все основания интерпретировать зафиксированные особенности объектов как случайные отклонения, обусловленные воздействием шумов, погрешностями измерительных приборов и т.п.
В задачах формирования знаний, когда мы имеем дело с системами надкибернетического уровня сложности, каждый объект следует рассматривать как самостоятельный информационный факт (совокупность зафиксированных значений признаков), имеющий ценные уникальные особенности.
Указанные особенности раскрываются путем конструирования для любого объекта собственного пространства признаков и нахождения индивидуальной меры, определяющих иерархию его сходства с другими объектами, релевантную заданному контексту. Без такого раскрытия описания объектов нивелированы, могут содержать много ненужных, шумящих, отвлекающих и даже вредных деталей, и "сферы действия" объектов как представителей своих классов эквивалентности являются суженными [14].
Конструирование собственного пространства признаков и нахождение индивидуальной меры будем называть локальным преобразованием пространства признаков. (Далее в докладе следует математическое обоснование, опущенное в данном тексте). Например, в случае бинарных признаков это может быть локальная взвешенная метрика Хэмминга.
Как следует из (1), задача определения контекстно-зависимой локальной метрики заключается в нахождении линейного преобразования новой векторной переменной . Для ее решения пригоден хорошо разработанный аппарат методов многомерного линейного анализа данных. Ограничение на применение этих методов накладывается требованием неотрицательности компонент весового вектора, так как различие объектов и по какому либо признаку должно обязательно приводить к увеличению расстояния либо в случае вообще не сказываться на изменении расстояния .
В рамках данной статьи ограничимся лишь общими замечаниями о методах построения локальных метрик. Критерий качества локальной метрики определяется контекстом, а его конкретная форма задается исследователем. Например. с учетом информации о принадлежности объектов к тем или иным классам эквивалентности это может быть стандартный для линейного дискриминантного анализа критерий, построенный на отношении разброса между классами к внутриклассовому разбросу. Или, имея в виду сложную неоднородную структуру классов, целесообразнее строить критерий качества на оценке первых к-ближайших объектов, то есть фактически на локальной оценке отношения правдоподобия в точке [15].
Также не лишен смысла критерий, основанный на сравнении расстояний от объекта до его q-ближайших соседей из собственного класса с расстояниями до его r-ближайших соседей из других классов и т.п.
При построении локальной метрики могут использоваться самые различные методы, ориентированные на максимизацию заданного критерия. Нередко достаточно ограничиться только отбором центрированных признаков в (1).
Это бывает целесообразно, главным образом, при работе с бинарными признаками. Для решения данной задачи особенно эффективны алгоритмы отбора переменных типа "плюс l минус r" [16] и эволюционные методы, в частности, как показывает опыт, хорошо себя зарекомендовал метод случайного поиска с адаптацией [17].
Индивидуально сконструированные локальные метрики обеспечивают каждому объекту, как представителю своего класса, максимально возможную "сферу действия", которой нельзя достигнуть при построении общего пространства признаков и использовании одинаковой метрики для всех объектов.
Описание каждого эмпирического факта оказывается полностью избавленным от неинформативных элементов, что позволяет в дальнейшем иметь дело с чистыми "незашумленными" структурами данных. В этом описании остается только то, что действительно важно для отражения сходства и различия эмпирического факта с другими фактами в контексте решаемой задачи.
В свете представлений о контекстно-зависимых локальных метриках очевидно, что один и тот же объект может поворачиваться разными гранями своего многомерного описания сообразно заданному контексту. К любому объекту, запечатленному в памяти как целостная многомерная структура, "привязан" набор различных локальных метрик, каждая из которых оптимизирует иерархию его сходства (различия) с другими объектами соответственно целям определенной задачи отражения отношений между объектами реального или идеального мира.
В результате построения локальных метрик отношения между объектами выражаются матрицей удаленностей Так как локальные метрики у разных объектов могут не совпадать, то для элементов матрицы могут не выполняться требования симметричности и неравенства треугольника. Поэтому данная матрица, хотя и отражает отношения различия между объектами, не может истолковываться как матрица расстояний. Для устранения нарушений метрических отношений между элементами матрицы вводится специальный класс -метрик. (Далее в докладе следует математическое обоснование, опущенное в данном тексте).
Образно говоря, если окинуть взором множество объектов с точки, занимаемой объектом , в пространстве, специально сконструированном для этого объекта, то для такого взора объекты выстроятся в специфический ряд по степени удаленности от данной точки. С другой точки и в другом пространстве ряд удаленностей тех же самых объектов будет иметь свой специфический вид.(Далее в докладе следует математическое обоснование, опущенное в данном тексте).
Выбор конкретного преобразования зависит от того, на каком аспекте структуры данных исследователь решает сделать акцент. Например, может использоваться преобразование в ранговую величину.
Другой вариант - преобразование в классификационный показатель. В этом случае все объекты, проранжированные по удаленности, заменяются идентификатором своего класса, образно говоря, "окрашиваются" в цвета своего класса. Выбор меры зависит, с одной стороны, от вида преобразования и, с другой стороны, от того, какие особенности рядов и объектов имеется намерение оттенить при определении их сходства (различия).
Прямой способ основан на вычислении расстояния (например, евклидова). В данном случае не требуется дальнейшего подбора констант и для соблюдения метрических требований, так как они выполняются автоматически.
Однако бывает более целесообразно использовать в качестве меры тот или иной коэффициент связи, например, коэффициент корреляции Пирсона, Кендалла и др.
Если преобразование дает классификационную переменную, то мерой подобия может служить какой-либо коэффициент сопряженности для номинальных переменных. (Далее в докладе следует математическое обоснование, опущенное в данном тексте).
После перехода от матрицы к матрице расстояний исследование совокупности объектов с привязанными к ним собственными локальными метриками может производиться всеми доступными методами и алгоритмами, использующими геометрическую метафору данных.
Сюда относятся алгоритмы автоматического группирования (кластерный анализ, иерархическое группирование, определение "точек сгущения") [22] и методы визуализации данных, для которых исходной информацией служит матрица расстояний (многомерное шкалирование [23], адаптивная развертка [14]).
Анализ геометрической структуры данных является творческой задачей, не имеющей штампов. Например, полезную информацию о стратификационной структуре матрицы расстояний можно получить с помощью алгоритмов иерархического группирования данных.
Осмысление выделенных группировок на различных шагах работы того или иного дивизимного или агломеративного алгоритма дает возможность получить ответы на вопросы, что общего и в чем различаются группировки объектов. Это в свою очередь способствует построению системы понятий, определению метапонятий и установлению между ними семантических отношений, то есть проведению концептуального анализа знаний.
Использование методов проецирования данных на плоскость или в 3-х мерные объемы латентных переменных, полученных методами многомерного шкалирования, позволяет увидеть закономерности структуры множества эмпирических фактов с оптимизированными описаниями.
С одной стороны, увиденные закономерности могут составить основу для минимизации базы знаний, представленных в экстенсиональной форме (например, для определения композиции диагностических прецедентов минимального объема).
С другой - выявленные закономерности способствуют разработке тех или иных интенсиональных правил вывода на знаниях.
Имеется еще одна ценная возможность использования визуальных отображений полученных геометрических структур данных. Ее предоставляют средства современной интерактивной графики, которые позволяют обосновывать принятие решения о принадлежности неизвестного объекта какому-либо классу эквивалентности, получая ответы на вопросы типа:
Ответы даются в виде пересечения описания неизвестного объекта с описаниями объектов, которые оптимизированы привязкой контекстно-зависимых локальных метрик. Совокупность таких ответов, индивидуальных для каждого нового случая, обладает полиморфностью, свойственной нашему языку при описании явлений со сложной системной организацией, и обеспечивает объяснение принятых решений посредством аргументации.
Здесь нет дерева логического вывода. Ответы воспринимаются параллельно. Они как бы бросаются на чашу весов и их множество может расширяться до довольно больших величин (в зависимости от количества привлекаемых для аргументации объектов и сочетаний объектов). Для иллюстрации некоторых из вышеперечисленных возможностей применения контекстно-зависимых локальных метрик и геометрического подхода рассмотрим следующий пример.
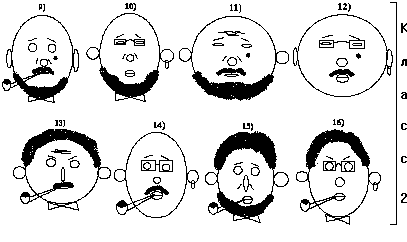
На рис.1 представлены изображения лиц 16 людей. Эти люди разбиты на два класса. Ставилась задача найти закономерности такого разбиения.
Прежде всего были выделены бинарные признаки, характеризующие изображенные лица. Это следующие признаки:
Рис.1. Исследуемые объекты
Исходная матрица данных, соответствующая изображенным лицам, представлена на рис.2. Строки соответствуют объектам (N=16), столбцы - бинарным признакам (p=16). Объекты с номерами 1-8 относятся к классу w1, а с номерами 9-16 - к классу w2.
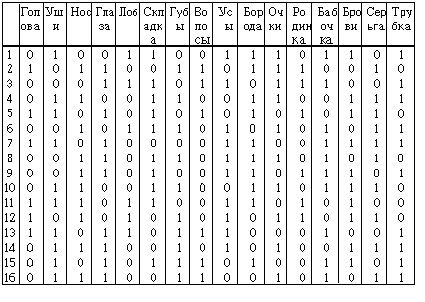
Рис.2. Исходная матрица данных
На первом этапе производился анализ представленных данных с помощью традиционных методов прикладной статистики, содержащихся в пакете StatGraphics Plus for Windous . Как показывает проведенный анализ, в исходном пространстве признаков объекты разных классов перемешаны друг с другом. Об этом говорят результаты иерархического группирования и проекция объектов в пространство первых 3-х главных компонент, на которые приходится более 52% общей дисперсии.
В то же время дискриминантный анализ привел к положительному эффекту разделения классов (применялась версия дискриминантного анализа с использованием процедур последовательного увеличения и уменьшения группы признаков). Получена следующая дискриминантная функция
g(x)=-1,7+73x2+2,4x4+7,4x7-55x8+1,6x10+10,0x12+4,9x13 (4)
Дискриминантная функция (4) обеспечивает полное разделение классов w1 и w2. Если стремиться только к формальному эффекту, то на таком убедительном результате разделения классов можно остановиться. Однако в данном случае достигнутому формальному эффекту в слабой степени сопутствует формирование новых знаний о структуре анализируемых данных.
Единственное, что можно сказать - это перечислить признаки и веса, с которыми они вошли в линейную дискриминатную функцию. "За кадром" остается внутреннее строение классов и данных в целом, которое, как будет показано ниже, может быть достаточно интересным и раскрытие которого может давать качественно новую информацию.
Указанное раскрытие с использованием контекстно-зависимых локальных метрик и изложенного геометрического подхода являлось целью второго этапа анализа данных. (Далее в докладе следует математическое обоснование, опущенное в данном тексте).
Локальные метрики вида для каждого объекта находились с помощью алгоритма случайного поиска с адаптацией (СПА) [17]. Проводилась серия опытов по случайному определению состава группы n признаков из множества исходных 16 признаков. Для каждой группы вычислялось значение критерия (5).
Группа с минимальным значением критерия поощрялась увеличением вероятности выбора ее признаков в следующих сериях опытов, а группа с наибольшей величиной наказывалась соответствующим образом. Эта процедура повторялась до тех пор, пока не выделилась группа признаков с явно преобладающей над другими вероятностью ее выбора. Количество опытов в серии, объем группы признаков, а также меры поощрения и наказания признаков подбирались эмпирически.
Результат работы алгоритма СПА показан на рис.3. Отметим, что применение на этих же данных алгоритма последовательного уменьшения группы признаков дало несущественно отличающиеся результаты.
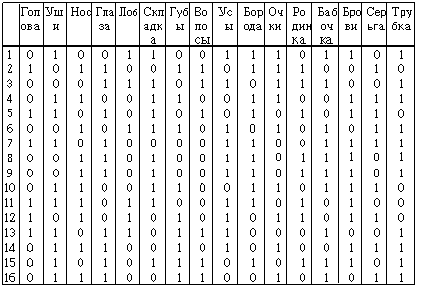
Рис.3.Результат работы алгоритма СПА
Следующим шагом анализа было вычисление расстояний между объектами с оптимизированными описаниями и группирование и признаков.
Как следует из приведенных рисунков, определение локальных метрик привело, как и при применении дискриминантного анализа, к полному разделению классов w1 и w2. Но при этом стало ясно, какую роль играют признаки и сочетания их значений в проявившейся структуре множества объектов. Видно, что для достижения полученного эффекта разделения классов важными оказались все признаки. В то же время в каждом классе выделилось по две самостоятельные группировки объектов, для каждой из которых характерно строго определенное сочетание значений собственных признаков.
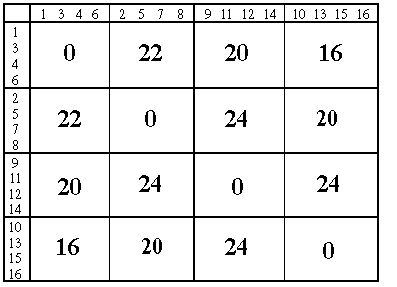
Рис.4. Структура множества объектов с привязанными к ним локальными метриками
В целом визуально структура множества объектов с привязанными к ним локальными метриками представляется в виде четырехгранника (рис.5).Исходя из полученной структуры, композицию, достаточную для представления классов и , составят 4 объекта (4 конъюнкции элементарных событий), по одному из выделенных группировок. Соответственно, правило вывода для принятия решения о принадлежности объектов какому-либо классу может иметь следующий вид
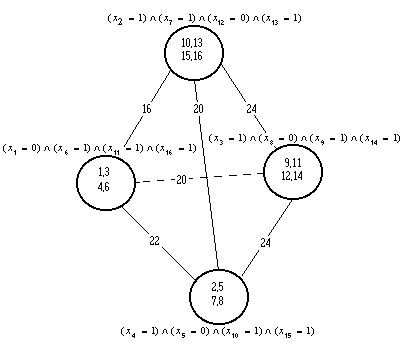
Рис. 5.Геометрическая структура логических закономерностей
На практике, конечно, встречаются гораздо более сложные ситуации, чем в приведенном примере.
Выбор этого примера обусловлен желанием простой и выразительной демонстрации некоторых возможностей применения контекстно-зависимых локальных метрик и геометрического подхода при решении задач формирования знаний. Он показывает, что построение для каждого эмпирического факта собственной локальной метрики, оптимизирующей в заданном контексте иерархию его геометрической близости к другим фактам, позволяет существенно уменьшить число элементарных событий, подлежащих дальнейшему анализу.
И, кроме того, геометрическое изображение структуры множества объектов с оптимизированными описаниями посредством локальных метрик дает наглядное визуальное представление об ее особенностях, что помогает формированию результирующего правила вывода.
Интересными представляются возможности применения описанного подхода для анализа совокупности объектов при отсутствии информации об их группировании в какие-либо классы. В этом случае в целях конструирования локальных метрик искусственно создается альтернативный класс из равномерно распределенных объектов.
Тогда сконструированные локальные метрики оптимизируют описание каждого объекта таким образом, что в нем остается только то, что является важным для выражения отличия структуры анализируемой совокупности от случайно организованной структуры данных.
Эта задача нуждается в самостоятельном рассмотрении. Описанный подход к формированию знаний может быть реализован в разнообразных вариантах. Это разнообразие обусловлено различными употребимыми критериями качества локальных метрик, алгоритмами определения их параметров и видами метрик. Здесь исследователю предоставляется широкое поле для экспериментирования и выбора наилучшего варианта при решении конкретной задачи формирования знаний.
Конкретные практические приложения геометрического подхода представляются наиболее эффективными в следующих областях:
Литература